Hi, In my last post related to AI models used in Drone technology, I have mentioned specifically importance of YOLO, so lot of people contacted me to know more about the same. So here a full post specially on YOLO.
What is YOLO?
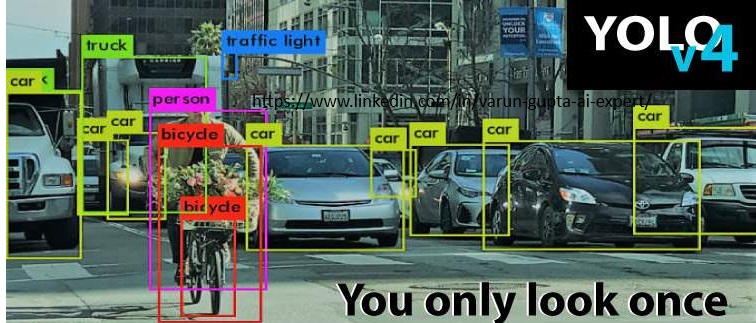
YOLO is a type of object detection model. It looks at an image once and finds all the objects in it—like people, cars, dogs, etc.—along with where they are (bounding boxes).
How it works (in simple steps):
- Divide the image into a grid
Imagine splitting the image into squares—like a chessboard. For example, a 7×7 grid. - Each square (grid cell) looks for objects
Each cell is responsible for detecting objects whose center falls inside it. - Each cell predicts:
- Bounding boxes: Where the object is.
- Confidence: How sure it is there’s an object.
- Class: What kind of object it is (like “cat” or “car”).
- All predictions are combined
YOLO looks at everything together and picks the best bounding boxes with high confidence.
Why it’s called “You Only Look Once”?
Because unlike older models that look at parts of the image many times (like scanning with a flashlight), YOLO looks at the whole image just once to make all predictions. That makes it very fast—great for real-time use, like self-driving cars or security cameras.
YOLO Model (Brain of Vision)
This is where the actual object detection happens. YOLO architecture inside the drone works like this:
🔹 Step-by-Step Inside YOLO:
| Layer/Block | Function |
| Backbone | Extracts features from the image (edges, textures, shapes). Often uses a CNN like Darknet, CSPDarknet, or MobileNet for lightweight performance. |
| Neck | Combines features at different scales (e.g., using FPN or PAN) so the model can detect both small and large objects. |
| Head | Predicts: |
- Bounding boxes (where objects are)
- Confidence score
- Class probabilities (what the object is)
For each grid cell in the image. |
Output: A list of detected objects with their locations and classes (e.g., “person at [x, y]”).
Follow me at: https://www.linkedin.com/in/varun-gupta-ai-expert/