The Retrieval-Augmented Generation (RAG) Developer Stack is a modern framework for building intelligent AI applications that blend the strengths of information retrieval and language generation. It combines the capabilities of Large Language Models (LLMs) with external data sources to deliver highly accurate, context-aware, and up-to-date responses.
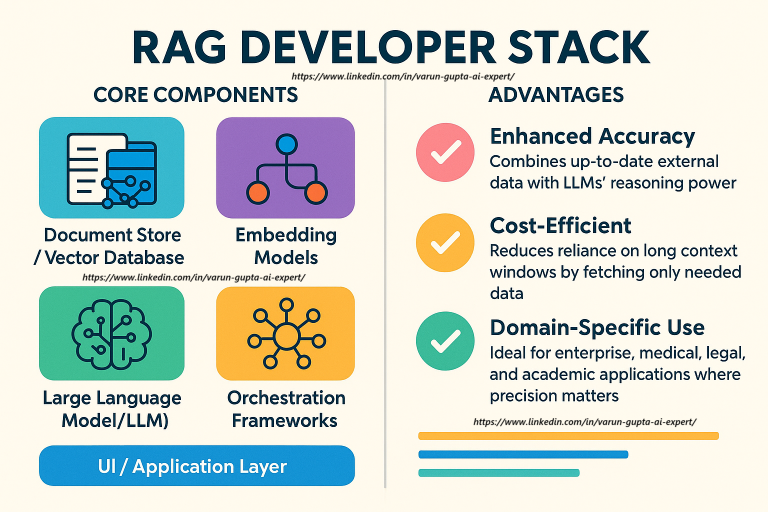
Core Components of the RAG Developer Stack:
- Document Store / Vector Database
At the heart of RAG lies a vector database (like FAISS, Weaviate, Pinecone, or Chroma), which stores documents or data chunks in an embedding format. This allows for fast semantic search and retrieval based on meaning rather than keywords. - Embedding Models
Tools like OpenAI Embeddings, Hugging Face Transformers, or Sentence-BERT convert textual data into vector representations, enabling efficient and relevant document retrieval. - Retriever
A retriever component queries the vector store with the user’s prompt (converted into an embedding), fetching the most relevant documents to supplement the LLM’s generation. - Large Language Model (LLM)
Models such as GPT-4, Claude, or LLaMA then generate responses using both the user’s input and the retrieved content — enhancing factual accuracy and grounding. - Orchestration Frameworks
Frameworks like LangChain, LlamaIndex, or Haystack manage the flow of data between components, handling prompt templating, chaining, memory, and decision logic. - UI / Application Layer
This includes front-end interfaces, APIs, or chatbot platforms that users interact with. Tools like Streamlit, Gradio, or custom web apps are commonly used.
Advantages of the RAG Stack:
- Enhanced Accuracy – Combines up-to-date external data with LLMs’ reasoning power.
- Cost-Efficient – Reduces reliance on long context windows by fetching only needed data.
- Domain-Specific Use – Ideal for enterprise, medical, legal, and academic applications where precision matters.
Final Thought:
The RAG developer stack represents a powerful and flexible approach to building next-generation AI systems. By combining retrieval and generation, developers can overcome the limitations of standalone LLMs and deliver AI that is both smart and reliable.