After I post my last article “𝗗𝗼 𝘆𝗼𝘂 𝗸𝗻𝗼𝘄 𝗵𝗼𝘄 𝗺𝘂𝗰𝗵 𝗶𝘁 𝗰𝗼𝘀𝘁𝘀 𝘁𝗼 𝘁𝗿𝗮𝗶𝗻 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 (𝗟𝗟𝗠𝘀)?”, I got lot of replies & queries that “why & where these costs are going”. So, with this article I’m trying to explain this. I hope everyone will get answer of their queries.
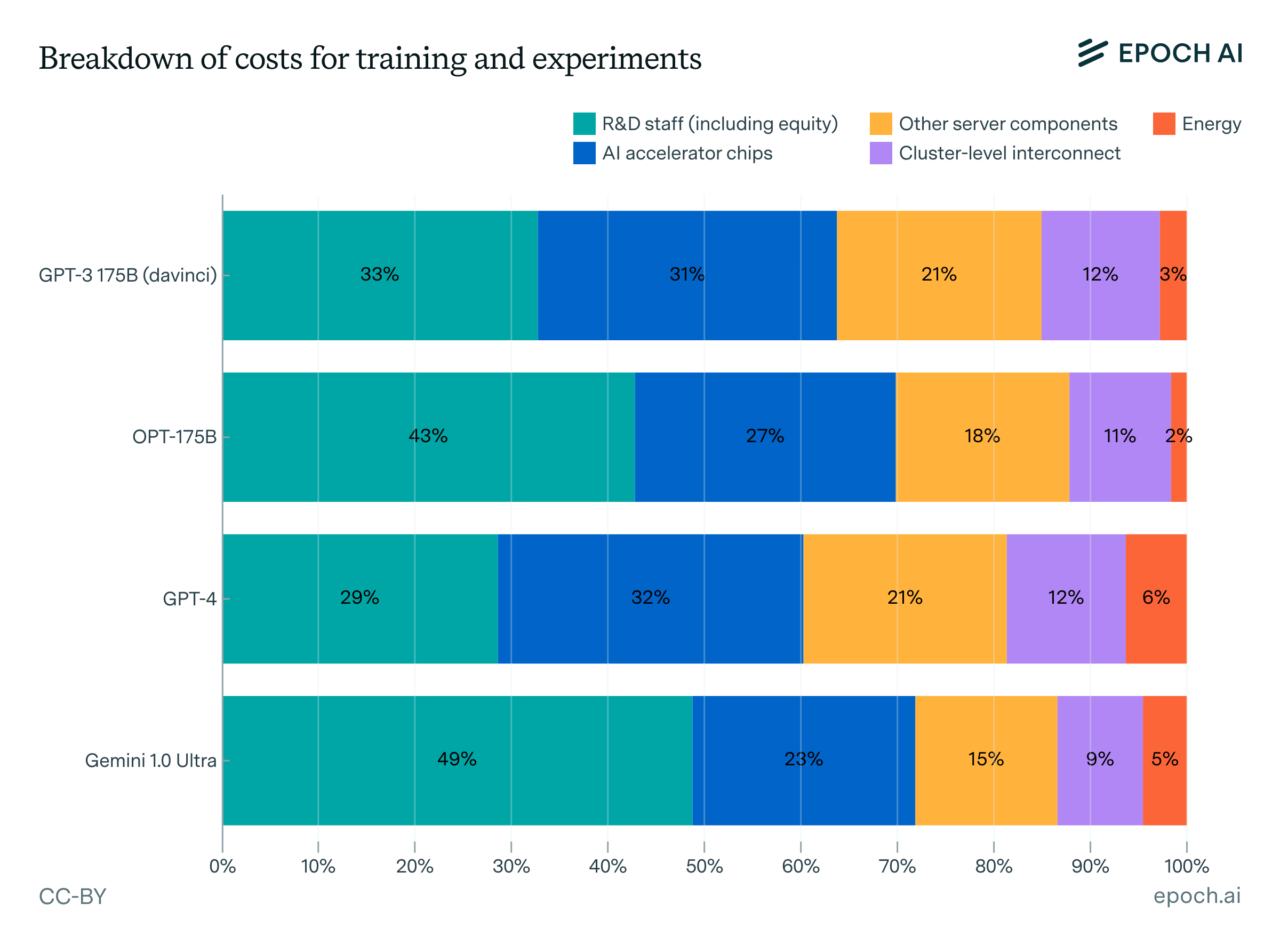
We estimated a cost breakdown to develop key frontier models such as GPT-4 and Gemini Ultra, including R&D staff costs and compute for experiments. We found that most of the development cost is for the hardware at 47–67%, but R&D staff costs are substantial at 29–49%, with the remaining 2–6% going to energy consumption.
If the trend of growing training costs continues, the largest training runs will cost more than a billion dollars by 2027
Hardware costs include AI accelerator chips (GPUs or TPUs), servers, and interconnection hardware
We also estimate the energy consumption of the hardware during the final training run of each model.
Using this method, we estimated the training costs for 45 frontier models (models that were in the top 10 in terms of training compute when they were released) and found that the overall growth rate is 2.4x per year.